
学习 CNN 的时候,很容易一上来就被各种网络名字淹没:LeNet、AlexNet、VGG、GoogLeNet、ResNet……它们看起来都叫“卷积神经网络”,但每一个出现的背景和解决的问题并不一样。
这篇笔记不追求把论文细节全部展开,而是先从小白能理解的角度,把五个经典结构串起来:
- LeNet:CNN 的早期雏形,证明卷积网络可以做图像识别
- AlexNet:让深度学习在 ImageNet 上爆发
- VGG:用很规整的小卷积核堆出深网络
- GoogLeNet:用 Inception 模块提高计算效率
- ResNet:用残差连接解决深层网络难训练的问题
如果你刚开始学计算机视觉,可以把这篇当成一张“CNN 发展路线图”。
目录
- 先理解 CNN 在做什么
- LeNet:CNN 的经典起点
- AlexNet:深度学习视觉时代的开端
- VGG:简单、规整、容易迁移
- GoogLeNet:让网络在不同尺度上看图像
- ResNet:让网络可以真正变深
- 五个网络放在一起怎么记
1. 先理解 CNN 在做什么
CNN,全称是 Convolutional Neural Network,中文一般叫卷积神经网络。
它最擅长处理图像,因为图像有两个非常明显的特点:
- 局部相关性:一个像素和周围像素关系很强,比如边缘、纹理、角点通常都出现在局部区域。
- 空间结构:图像不是一串无序数字,左上、右下、上下左右的位置关系都很重要。
普通全连接网络会把图片拉平成一个长向量,这样会破坏很多空间信息。而 CNN 会保留图像的二维结构,通过卷积核在图像上滑动,逐步提取特征。
一个最基础的 CNN 通常由这些部分组成:
| 组成部分 | 作用 | 小白理解 |
|---|---|---|
| 卷积层 | 提取局部特征 | 像一个小窗口,在图像上寻找边缘、纹理、形状 |
| 激活函数 | 加入非线性 | 让网络不只是做简单线性变换 |
| 池化层 | 降低特征图尺寸 | 保留主要信息,减少计算量 |
| 全连接层 | 输出分类结果 | 根据前面提取的特征判断类别 |
可以把 CNN 理解成一个从低级到高级的识别过程:
原始像素
↓
边缘、颜色、简单纹理
↓
局部形状、部件
↓
完整物体特征
↓
分类结果
下面的五个网络,就是 CNN 从“能用”到“很深、很强、很高效”的几个重要阶段。
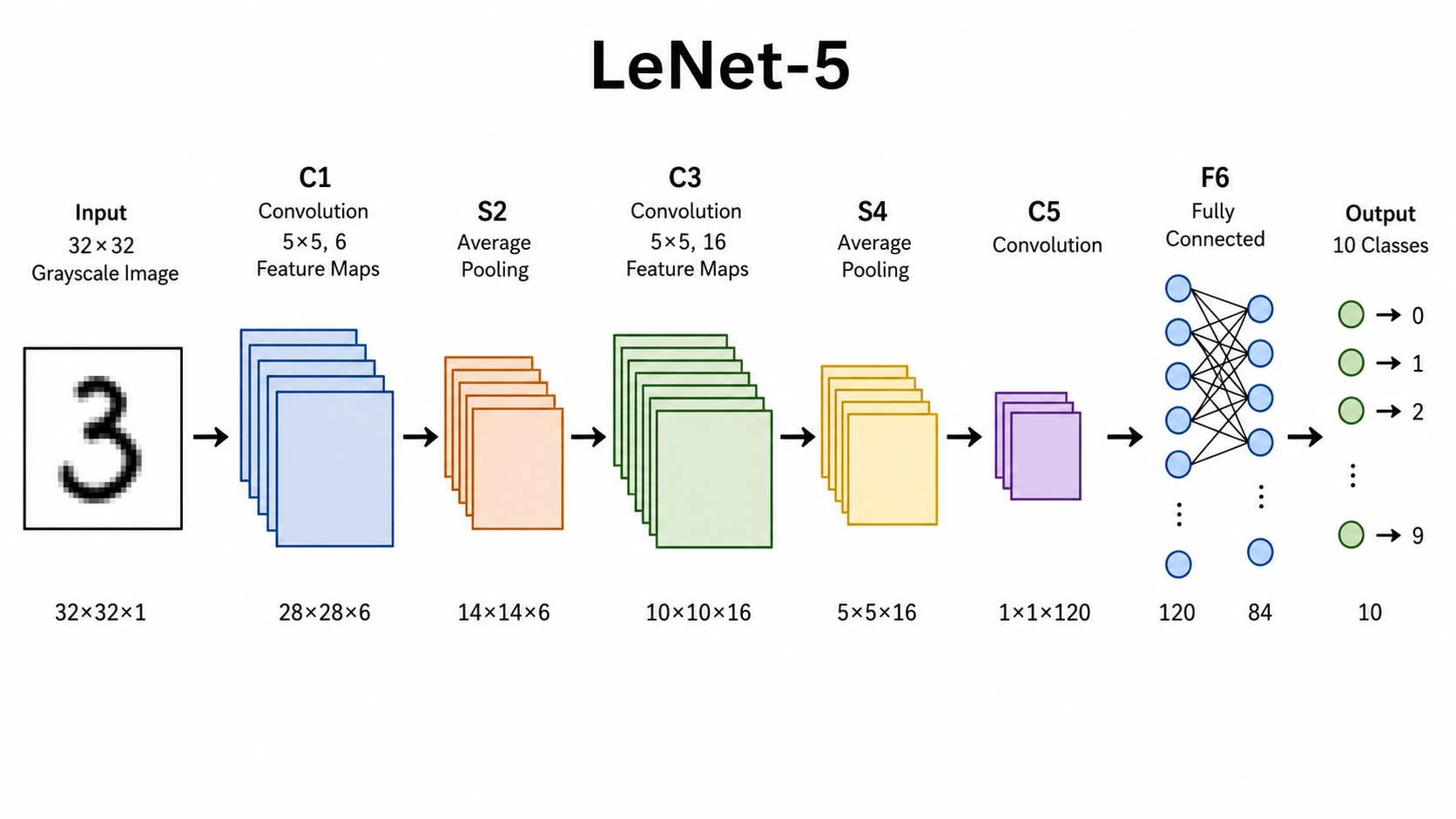
2. LeNet:CNN 的经典起点
LeNet 通常指 LeNet-5,由 Yann LeCun 等人在 1998 年提出,最早主要用于手写数字识别,比如识别支票、邮政编码里的数字。
2.1 它解决了什么问题?
在 LeNet 之前,图像识别更多依赖人工设计特征。比如你要识别数字 8,可能需要人为设计“有没有闭环”“上下是否对称”等特征。
LeNet 的意义在于:它让模型自己从数据中学习特征。
也就是说,不再完全依赖人手写规则,而是让卷积层自己学会哪些局部形状对分类有用。
2.2 LeNet 的结构怎么理解?
LeNet 的整体结构比较简单:
输入图像
→ 卷积层
→ 池化层
→ 卷积层
→ 池化层
→ 全连接层
→ 输出类别
它有两个非常重要的思想:
- 卷积提特征:用卷积核扫描图像,提取局部模式。
- 池化做压缩:降低特征图大小,让后面的计算更轻。
2.3 小白应该记住什么?
LeNet 不复杂,但它奠定了 CNN 的基本模板:
卷积 → 池化 → 卷积 → 池化 → 分类
后来很多 CNN 虽然变得更深、更复杂,但基本思想还是从这里发展出来的。
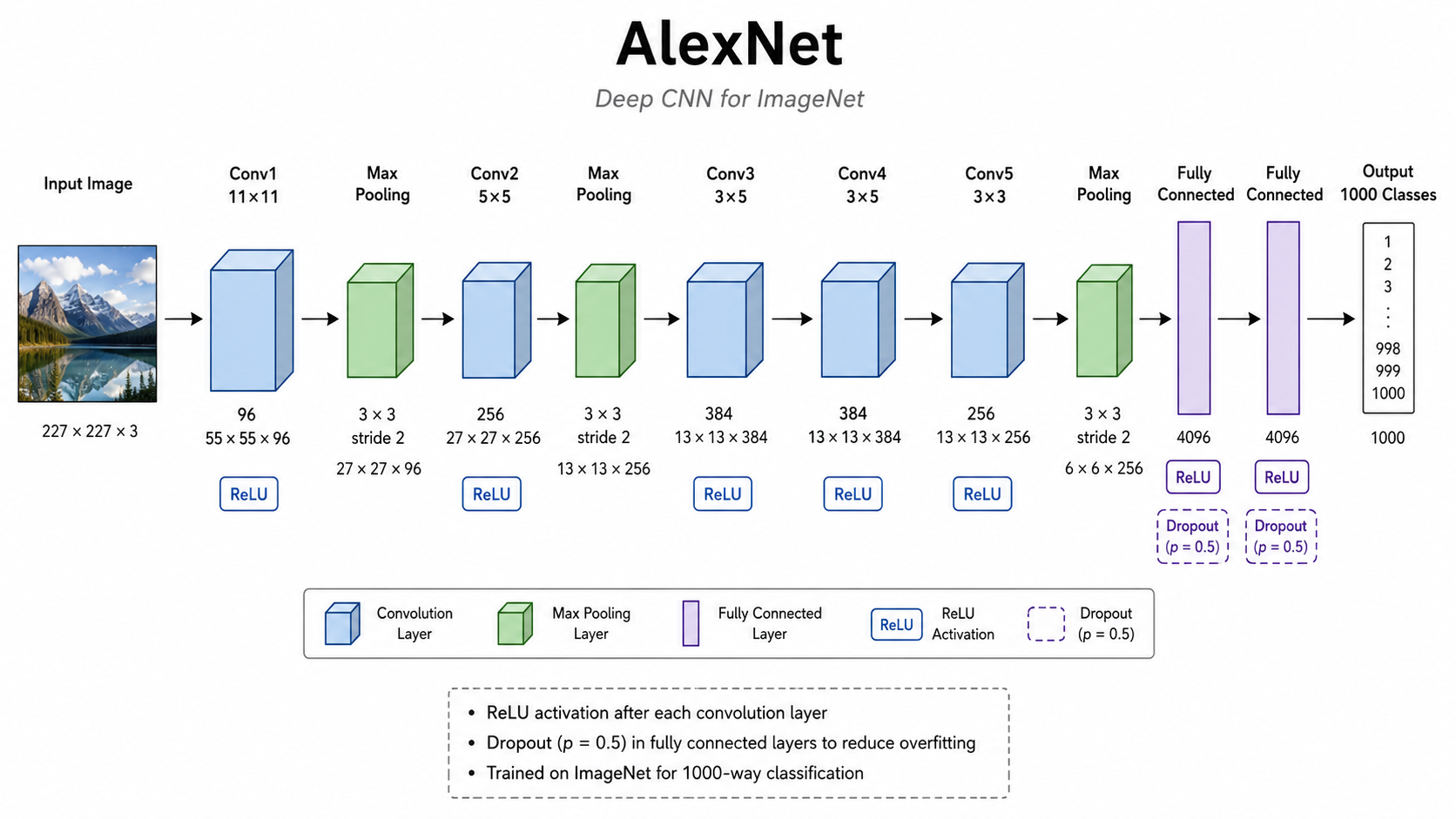
3. AlexNet:深度学习视觉时代的开端
AlexNet 是 2012 年 ImageNet 比赛中的冠军模型。它的出现通常被认为是深度学习在计算机视觉领域真正爆发的标志。
3.1 为什么 AlexNet 这么重要?
ImageNet 是一个大规模图像分类数据集,类别多、图片多,难度远高于手写数字识别。
AlexNet 在这个比赛中大幅领先传统方法,说明深层 CNN 可以在大规模自然图像上取得非常强的效果。
它的重要性不只是“准确率高”,而是证明了几件事:
- 深层网络真的可以训练起来
- GPU 可以显著加速深度学习训练
- 大数据 + 深模型 + 强算力 是计算机视觉突破的重要组合
3.2 AlexNet 的关键设计
AlexNet 比 LeNet 更深,大致由多个卷积层和全连接层组成。
它有几个经典设计:
| 设计 | 作用 |
|---|---|
| ReLU 激活函数 | 相比 sigmoid/tanh,更容易训练深层网络 |
| Dropout | 减少全连接层过拟合 |
| 数据增强 | 通过裁剪、翻转等方式增加训练样本变化 |
| GPU 训练 | 让大规模 CNN 训练变得可行 |
其中 ReLU 很关键。它的形式很简单:
ReLU(x) = max(0, x)
输入大于 0 就保留,小于 0 就变成 0。这个简单函数让深层网络训练速度明显提升。
3.3 小白应该记住什么?
AlexNet 的意义是把 CNN 从“小规模任务”推向了“大规模真实图像分类”。
如果 LeNet 证明了 CNN 能做图像识别,那么 AlexNet 证明了:深层 CNN 可以在大数据上击败传统视觉方法。
4. VGG:简单、规整、容易迁移
VGG 是 2014 年提出的经典网络,常见版本有 VGG-16 和 VGG-19。这里的数字表示网络中带参数的层数。
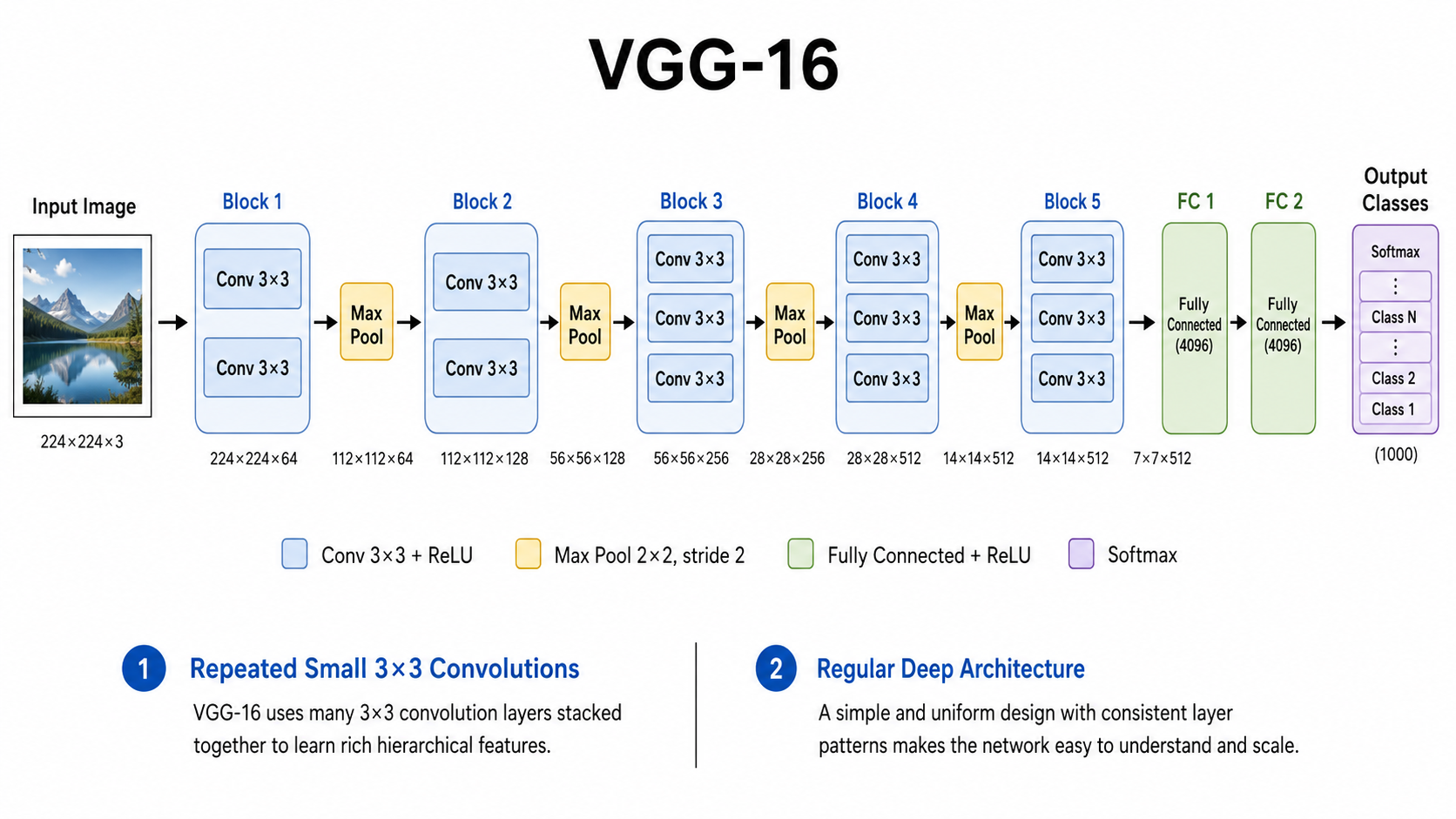
4.1 VGG 的核心思想
VGG 最有代表性的特点是:大量使用 3×3 小卷积核,并把它们重复堆叠起来。
你可能会问:为什么不用一个大的卷积核,比如 5×5 或 7×7?
原因是多个 3×3 卷积堆起来,也可以获得较大的感受野,同时参数量更可控,还能引入更多非线性。
例如,两个 3×3 卷积连续堆叠后,看到的区域大致相当于一个 5×5 感受野:
3×3 卷积 → 3×3 卷积 ≈ 5×5 感受野
三个 3×3 卷积连续堆叠后,感受野大致相当于 7×7。
4.2 VGG 为什么适合学习?
VGG 的结构非常规整,基本就是不断重复:
卷积 → 卷积 → 池化
卷积 → 卷积 → 池化
卷积 → 卷积 → 卷积 → 池化
...
全连接 → 分类
这种结构的优点是容易理解,也容易作为特征提取器使用。
在很多早期迁移学习任务中,人们会直接拿预训练好的 VGG,把最后的分类层换掉,用来做自己的任务。
4.3 VGG 的不足
VGG 的缺点也很明显:参数量很大,尤其是后面的全连接层非常重。
所以它虽然经典,但在实际部署中不一定高效。后来很多网络都在尝试解决一个问题:怎么在保持准确率的同时减少计算量和参数量?
4.4 小白应该记住什么?
VGG 可以用一句话概括:
用简单统一的 3×3 卷积不断堆叠,构造更深的 CNN。
它的价值在于结构清晰,非常适合入门者理解“深度增加”这件事。
5. GoogLeNet:让网络在不同尺度上看图像
GoogLeNet 是 2014 年 ImageNet 比赛中的冠军模型,也叫 Inception v1。注意它的名字中间是 LeNet,完整写法常见为 GoogLeNet。
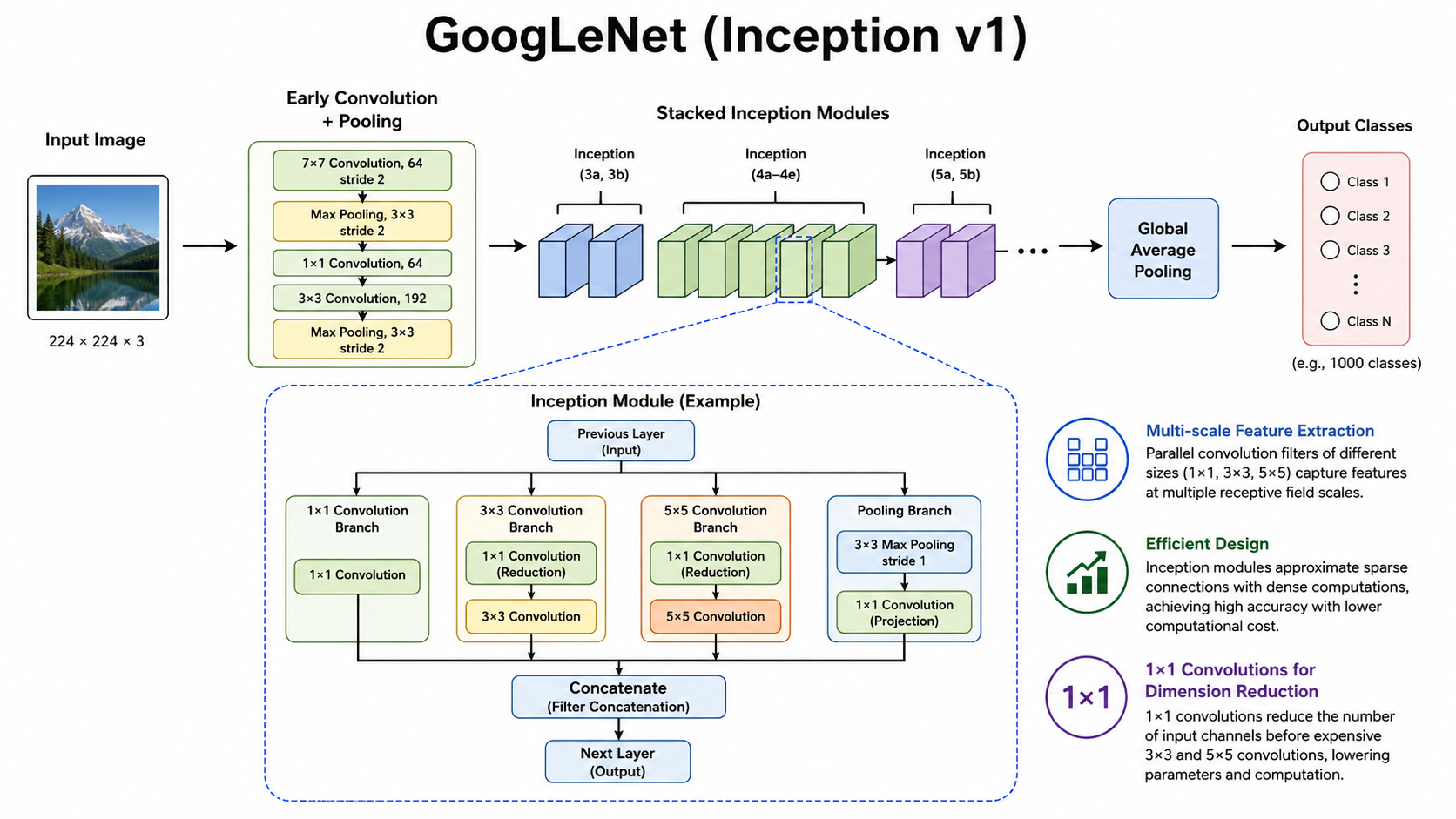
5.1 为什么需要 Inception?
前面的网络大多是“一层接一层”地往下堆。但图像里的物体大小并不固定:
- 有些特征很小,比如边缘、角点
- 有些特征稍大,比如眼睛、轮子
- 有些特征更大,比如脸、车身
如果只用一种卷积核尺寸,可能不够灵活。
GoogLeNet 的想法是:在同一层里并行使用多种尺度的卷积,再把结果拼接起来。
5.2 Inception 模块怎么理解?
一个简化的 Inception 模块可以理解为:
输入特征图
├── 1×1 卷积
├── 3×3 卷积
├── 5×5 卷积
└── 池化
↓
拼接输出
这样做的好处是,网络可以同时从不同尺度观察图像。
小卷积核擅长看局部细节,大卷积核能看到更大范围的信息,池化分支则提供另一种压缩后的特征。
5.3 1×1 卷积的作用
GoogLeNet 里大量使用 1×1 卷积。刚接触时可能会觉得奇怪:1×1 这么小,能提取什么空间特征?
其实 1×1 卷积主要不是为了看空间范围,而是为了调整通道数。
可以把它理解成:
在每个像素位置上,对不同通道的信息做一次重新组合
它常用于降维,减少后续 3×3、5×5 卷积的计算量。
5.4 小白应该记住什么?
GoogLeNet 的关键词是:
- Inception 模块
- 多尺度并行卷积
- 1×1 卷积降维
- 更高效地利用计算资源
它不只是单纯把网络加深,而是在思考:怎么让网络结构更聪明、更高效。
6. ResNet:让网络可以真正变深
ResNet 是 2015 年提出的残差网络,在深度学习历史上非常重要。它解决了一个关键问题:网络越来越深以后,反而可能更难训练。
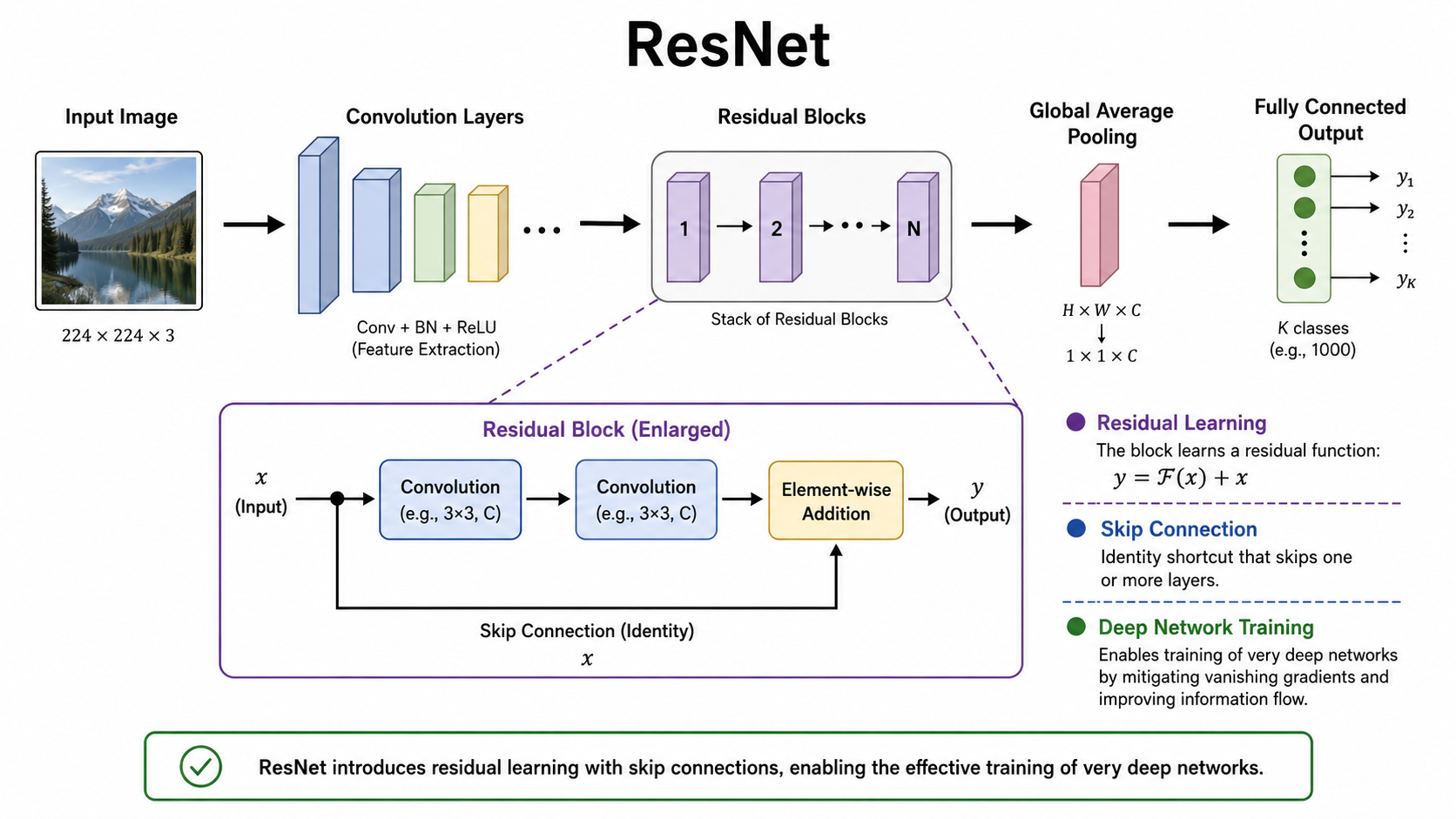
6.1 深层网络为什么不好训练?
直觉上,网络越深,表达能力应该越强。但实际训练时会遇到问题:
- 梯度在反向传播中变得很弱,前面的层学不动
- 层数增加后,优化难度变大
- 更深的网络不一定比浅层网络效果好
这不是简单的过拟合问题,而是深层网络本身训练困难。
6.2 残差连接是什么?
ResNet 的核心设计是残差块。普通网络学习的是:
H(x)
也就是直接学习输入到输出的完整映射。
ResNet 改成学习:
F(x) = H(x) - x
最后输出时再把输入加回去:
H(x) = F(x) + x
结构上可以理解为:
输入 x
├───────────────┐
↓ │
卷积 → 卷积 → F(x)│
↓ │
F(x) + x ←──┘
↓
输出
这条直接把输入传到后面的路径,通常叫 shortcut connection 或 skip connection。
6.3 为什么残差连接有用?
残差连接的好处可以从两个角度理解。
第一,它让网络更容易学习“什么都不改变”。如果某几层暂时学不到有用东西,至少可以让输入直接传过去,不至于把信息破坏掉。
第二,它让梯度更容易往前传。反向传播时,梯度可以沿着 shortcut 路径流动,缓解深层网络训练困难的问题。
所以 ResNet 让人们可以训练 50 层、101 层甚至更深的网络。
6.4 小白应该记住什么?
ResNet 的核心就是一句话:
不让每一层都强行重新学习全部映射,而是学习“在原输入基础上需要改多少”。
这个思想后来影响非常大,不只是在 CNN 中,在 Transformer 等模型里也能看到类似的残差连接。
7. 五个网络放在一起怎么记
最后把这五个网络放在一张表里,方便复习。
| 网络 | 年份 | 核心特点 | 主要意义 |
|---|---|---|---|
| LeNet | 1998 | 卷积 + 池化 + 全连接 | 奠定 CNN 基本结构 |
| AlexNet | 2012 | ReLU、Dropout、GPU、大规模训练 | 引爆深度学习视觉应用 |
| VGG | 2014 | 大量堆叠 3×3 小卷积 | 结构规整,适合理解深 CNN |
| GoogLeNet | 2014 | Inception 模块,多尺度并行卷积 | 在准确率和计算量之间做平衡 |
| ResNet | 2015 | 残差连接,shortcut | 解决深层网络难训练问题 |
如果按 CNN 发展的主线来看,可以这样理解:
LeNet:CNN 基本模板出现
↓
AlexNet:深层 CNN 在大规模图像分类中爆发
↓
VGG:用统一小卷积核把网络规整地加深
↓
GoogLeNet:用 Inception 模块提高多尺度表达和计算效率
↓
ResNet:用残差连接让非常深的网络也能训练
对入门者来说,不需要一开始就记住每一层的具体参数。更重要的是理解每个网络背后的问题:
- LeNet 解决“CNN 能不能做图像识别”
- AlexNet 解决“大规模真实图像上 CNN 有没有优势”
- VGG 解决“怎么用简单规则构建更深网络”
- GoogLeNet 解决“怎么兼顾多尺度特征和计算效率”
- ResNet 解决“网络很深以后怎么训练”
理解了这条线,再去看后来的 DenseNet、MobileNet、EfficientNet,甚至视觉 Transformer,都会更容易抓住重点。
小结
这五个网络不是孤立的名字,而是 CNN 发展过程中的几个关键节点。
LeNet 给出了卷积神经网络的基本雏形,AlexNet 证明深度学习可以在大规模视觉任务中取得突破,VGG 用极其规整的方式展示了深度的重要性,GoogLeNet 开始关注多尺度和计算效率,ResNet 则解决了深层网络训练困难的问题。
如果你刚开始学 CNN,建议先抓住每个网络的“核心贡献”,再逐步深入具体结构和论文细节。这样学起来不会被层数、参数和公式压垮,也更容易理解它们为什么经典。